AutoCast: Scalable Infrastructure-less Cooperative Perception for Distributed Collaborative Driving
Hang Qiu
Pohan Huang
Namo Asavisanu
Xiaochen Liu
Konstantinos Psounis
Ramesh Govindan
University of Southern California
Paper | Code | Demo | Bibtex
|
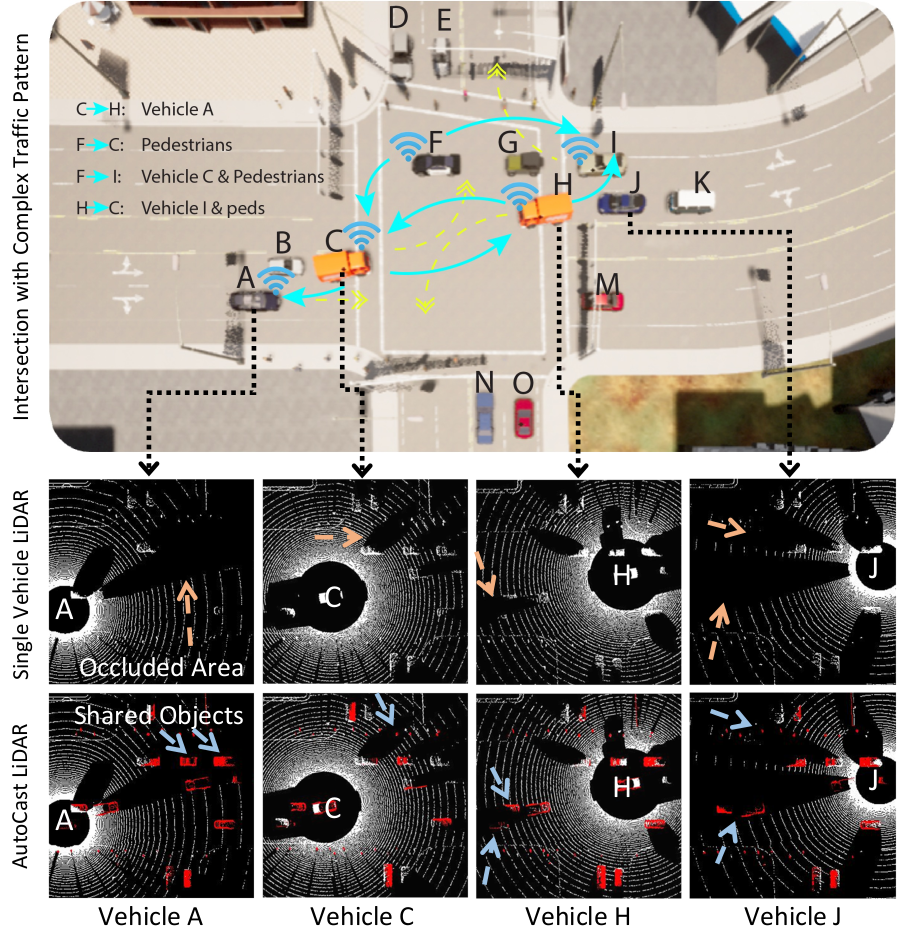
AutoCast Overview
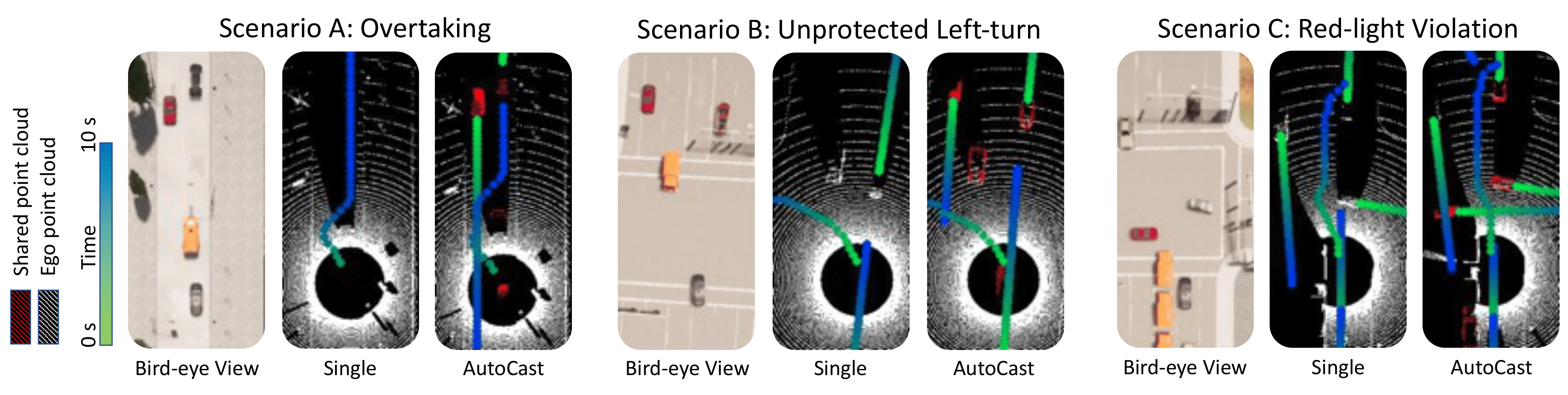
Evaluation Scenarios
|
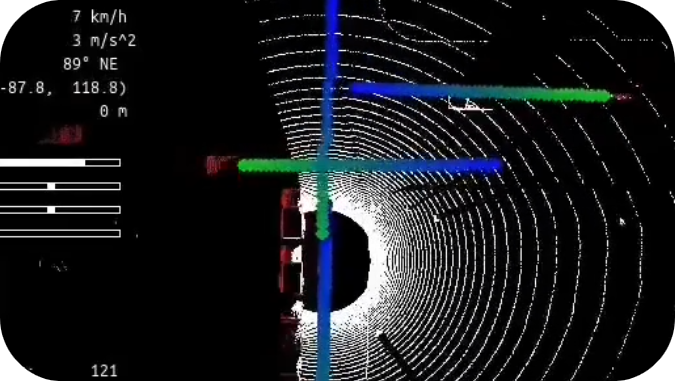
Qualitative Results



Citation
|
